
Autoscaler 를 이용해 Pod 와 Node 를 Scale out/in 해보자.
Autoscaling 이란?
1. Who is Autoscaling
- Horizontal pod autoscaling : Contoller에 의해 관리되는 Pod 의 Replicas 수가 자동으로 스케일링 되는 것
- HPA(Horizontal Pod Autoscaler)가 Scaling 설정한다.
- Cluster Autoscaler : Cluster 자체의 Node 수를 동적으로 조정하여 스케일링 되는 것
2. How is Autoscaling
- Controller가 주기적으로 Metric을 확인한다.
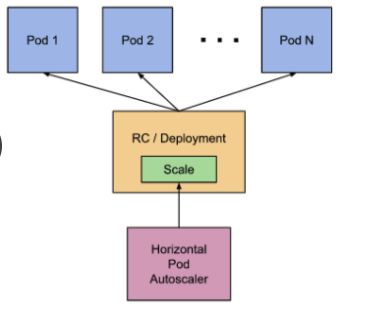
위와 같이 Kubernetes에서는 Pod 를 직접 생성하는 것이 아니라 RC(ReplicaSet), Deployment 와 같은 오브젝트를 통해 생성된다.- Deployment : Pod 의 배포 및 Scaling을 관리하는 Controller이다. Deployment는 ReplicaSet을 이용하여 Pod 를 생성하고 관리한다. ReplicaSet은 특정 개수의 Pod 복제본을 유지하도록 보장하며, Pod 상태를 모니터링하고 문제가 발생한 경우 복제본을 다시 생성해주고 있다.
- HPA Resource에 설정된 Target Value 값을 만족하는 Replica 수를 계산한다.

- kubelet에서 실행되는 cAdvisor에 의해 Metric이 수집된다.
*cAdvisor(Container Advisor)란, kubelet에 내장된 도구중 하나로 각 노드에서 실행중인 컨테이너의 CPU, Memory, 파일 디스크럽터, 네트워크 등 다양한 정보를 수집합니다. 이 정보들은 Kubernetes API 서버로 전송하여 모니터링, 로깅, 알람, Autoscaling과 같은 Kubernetes 기능을 가능하게 합니다. - 수집된 Metric은 metircs-server에 의해서 집계된다. (kubectl top 명령어를 사용하여 조회할 수 있다)
- kubelet에서 실행되는 cAdvisor에 의해 Metric이 수집된다.
- Horizontal Controller는 REST를 통해 모든 Pod의 metric을 가져온다. (정확히는 kubelet에 있는 cAdvisor가 담당)
- Pod의 모든 Metric 값을 더한 뒤, HPA에 정의된 target value로 나누고, 큰 정수로 반올림한다.
CPU 사용량을 기준으로 Autoscaling 해보자.
- 주의할 점 : Autoscaler가 Pod의 CPU Utilization을 결정할 때, 실제 사용량과 요청(Requests) 양을 비교한다.
- 즉, Autoscaling이 필요한 Pod는 Request가 명시 되어야 한다.
CPU Utilization 기반의 HPA를 생성해보자.
1. metrics-server를 설치한다.
https://github.com/kubernetes-sigs/metrics-server#installation위 사이트 들어가 따라 설치하면 된다.
설치 확인
kubectl get apiservice v1beta1.metrics.k8s.io -o jsonpath='{.status.conditions[?(@.type=="Available")].status}'
True로 나오면 설치가 잘 된 것이다.
2. Deployment를 생성하거나, 타 리소스를 생성 할 때 request를 적어준다.

- 위에서는 Pod 의 'resources' 섹션에서 'limits' 및 'requests' 을 설정하여 CPU 요청을 지정했다.
- 즉 requests 값은 Pod 가 필요로하는 최소 CPU 리소스를 지정하는 값이다. 이 값은 Pod 가 정상적으로 실행되기 위해 보장받아야 하는 CPU 리소스의 최소량을 나타낸다.
3. HPA를 생성한다.
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
- HPA를 생성하여 파드의 CPU 사용량이 50% 도달하면 스케일링을 수행하도록 설정했다.
kubectl edit hpa php-apache- Target 과 Metric 을 변경가능하다.

4. HPA 현재 상태를 확인한다.
kubectl get hpa
- 현재 서버로 요청을 보내는 클라이언트가 없기 때문에 현재 CPU 사용량이 0% 임을 확인할 수 있다.
5. 부하를 증가시켜보자.
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"*load-generator 는 Kubernetes 클러스터 내에서 애플리케이션에 부하를 주고 메트릭을 수집하는 툴입니다.



Pod가 10개까지 잘 증가 한 것을 확인할 수 있었다.
6. 이제 Scale-in 확인한다.
부하를 주던 load-generator Pod 를 삭제해주었다.

- php-apache pod 가 하나로 줄어든 것을 확인할 수 있었다.
Cluster nodes를 Autoscaling 하자.
Cluster Autoscaler는 node에 resource가 부족해서 scheduling 할 수 없는 pod를 발견하면, node를 추가 공급한다.
1. Scale up
- cluster autoscaler는 사용 가능한 Node group을 확인한다.
- 최소한 하나의 node 유형이라도 Pod 를 수용할 수 있는지 확인한다.
- Node를 추가한다.
2. Scale down
- 특정 node에서 실행 중인 모든 Pod의 resource가 50% 미만이면 해당 노드를 불필요한 node라고 생각한다.
하지만 두가지로 나눌 수 있다.- node를 종료할 수 없는 경우
- system pod가 실행중
- 관리되지 않는 pod, local volume을 가진 pod가 실행중
- node를 종료하는 경우
- 실행되는 pod가 다른 노드로 스케줄링 가능
1. 제거 대상 node가 더 이상 pod를 스케줄링 할 수 없는 상태로 전환
2. node에 속한 모든 pod를 삭제
3. node 삭제 후, CSP에 반환
- 클러스터 상세 정보 탭에 표시되는 노드풀 목록에서 ptty-nodepool을 선택해 주었다.
- [수정] 버튼을 클릭해 설정 버튼을 클릭한 후 최소, 최대 노드 수를 지정한다.

Deploy Cluster Autoscaler
- 우선 Cluster Autoscaler Yaml 파일을 다운로드 한다.
curl -o cluster-autoscaler-autodiscover.yaml https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
- 적용한다.
kubectl apply -f cluster-autoscaler-autodiscover.yaml
- cluster-autoscaler.kubernetes.io.safe-to-evict를 추가하기 위해 아래와 같이 patch 한다.
kubectl patch deployment cluster-autoscaler \
-n kube-system \
-p '{"spec":{"template":{"metadata":{"annotations":{"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"}}}}}'
- 이렇게 패치를 적용하면 cluster-autoscaler는 해당 node를 안전하게 비우거나 삭제할 수 있게 된다.
*주의할 점 : 이 주석이 특정 노드에서만 적용되므로 필요한 모든 노드에 대해 이 작업을 반복해야 한다.

- 위 파일은 현재 deployment 이다. 이제 페이지 확인 하여 버전 수정 후 적용한다.
https://github.com/kubernetes/autoscaler/releases
relases 페이지를 방문하여 최신 버전을 확인하여 적용한다.
- 이미지를 업데이트 함으로써 새로운 버전의 'cluster-autoscaler'를 사용하여 최신 버전의 기능과 보안 패치를 적용할 수 있게 된다.
kubectl set image deployment cluster-autoscaler \
-n kube-system \
cluster-autoscaler=k8s.gcr.io/autoscaling/cluster-autoscaler:v1.27.0
Cluster Autoscaler 를 Deploy 한 후에 로그를 확인하여 제대로 동작하는지 확인한다.

- Cluster Autoscaler을 동작을 확인하기 위해서는 해당 컴포넌트의 로그를 확인해야한다. Kubernetes 클러스터의 'kube-system' 네임스페이스에 위치하며, 'cluster-autoscaler' deployment의 pod 에서 확인 할 수 있다.
Autoscaler 정상 동작 확인
kubectl --kubeconfig=/root/kubeconfig.yaml get cm cluster-autoscaler-status -o yaml -n kube-system위 명령어는 'kube-system'네임스페이스에 있는 'cluster-autoscaler-status'라는 ConfigMap을 가져와 YAML 형식으로 출력한다.
- Scale Up 과 Scale Down 의 LastTransitionTime 을 확인해보면 리소스의 상태가 마지막으로 변경된 시간을 나타낸다. 따라서 Scale Up 과 Down 이 원활하게 이루어지는 것을 확인할 수 있다.

- 앞서 설정한 최대 노드수인 4로의 확장이 원활하게 이루어졌다.
궁금했던 점
- Node 추가 생성 Autoscaler 작동은 어떤방식으로 이루어 지는가?
- ClusterAutoScaler는 HPA 설정과는 별개의 로직으로 진행된다. 파드가 증가하여 클러스터의 리소스 부족으로 Pod가 스케줄링 되지 못할 때 (Pending) 상태일 때 스케일업을 진행한다. 파드가 증가하여도 스케줄에 문제가 없다면 스케일은 변경되지 않는다.
ClusterAutoscaler는 클러스터의 현재 상태와 파드의 스케줄링 가능 여부를 고려하여 자동으로 스케일 조정을 수행한다.
사용하고 있는 클러스터 내부에서 파드의 펜딩 상태가 발생하였고 이로 인해 각각 해당 시간 워커노드가 증가한 것으로 확인되었다.
노드 개수 3 : '2023-05-16 20:05:47'
노드 개수 4 : '2023-05-16 20:21:07'
- 시간은 얼마나 걸리는가?
- 요청 이후 워커노드의 준비 시간은 수분~수십분이 소요된다고 한다. 스케일업 결정 이후 워커노드가 증가하는 방식 - HPA 의 작동 방식은 어떻게 되는가?
CPU 사용률(%) = (파드의 CPU 사용량 / 파드의 CPU 요청) * 100 으로 현재 나의 request 값은 200m 이므로 50%인 100m 가 넘어가면 파드 수를 증가시킬 것이다.
되돌아보며
Cluster Autoscaler는 HPA(Horizontal Pod Autoscaler) 설정과 별개로 동작한다. HPA는 파드의 수를 동적으로 조정하여 애플리케이션의 수평 스케일링을 수행하는 반면, Cluster Autoscaler는 클러스터 자체의 노드 수를 관리하여 클러스터 전체의 용량을 조절한다. 따라서 파드 수의 증가가 스케쥴링에 문제가 없는 경우에는 스케일 업이 발생하지 않는다.
'Kubernetes' 카테고리의 다른 글
| [CKA] Mock Exam - 1 (0) | 2023.09.06 |
|---|---|
| [Kubernetes] HPA Monitoring with Prometheus (0) | 2023.08.11 |
| [Kubernetes] Pod CPU / Memory resource 최적화하기 (0) | 2023.08.11 |
| [Kubernetes] VPA를 사용하여 Pod의 Autoscaling 해보자 (0) | 2023.08.10 |
| [Kubernetes] Pod Scheduling (0) | 2023.08.10 |