
CLOVA Speech 란?
네이버 클라우드 플랫폼의 CLOVA Speech는 CLOVA의 NEST(Neural End-to-end Speech Transcriber) 음성 인식 기술을 통해 빠르고 쉬운 음성 인식 서비스를 제공합니다. CLOVA Speech를 이용하여 길이가 긴 미디어 파일의 음성을 간편하게 텍스트로 변환하고, 음성 메모, 영상 자막 생성, 통화 녹취록 관리 등 음성 기반 서비스를 만들 때 활용할 수 있습니다.

CLOVA Speech 시나리오
1. 사용 권한설정
2. 도메인 생성
3. 인식 작업 등록
4. 인식 결과 편집 및 내보내기
1. 사용권한 설정
CLOVA Speech를 사용하기 위한 사용 권한을 설정합니다. Sub Account에서 제공하는 서브 계정을 활용하여 CLOVA Speech의 관리자 권한과 사용자 권한을 구성할 수 있습니다.
2. 도메인 생성
네이버 클라우드 플랫폼 콘솔에서 도메인을 생성합니다.
CLOVA Speech에서는 도메인을 생성하여 도메인별로 인식 작업을 관리할 수 있습니다. 도메인별로 인식 대상 파일 및 결과 파일의 저장 경로를 설정할 수 있으며, 도메인별로 제공되는 빌더를 통해 인식 작업을 요청 할 수 있습니다.

빌더 실행 화면

빌더를 실행할 도메인의 [빌더 실행] 버튼을 클릭해 주면 됩니다.
3. 인식 작업 등록
인식 작업을 등록합니다. 빌더를 통해 인식 작업을 요청하거나, 배치를 생성하여 다수의 미디어 파일의 인식 작업을 일괄 처리할 수 있습니다.

파일이 잘 업로드 되었다면 요청시작 버튼을 눌러주면 됩니다.

인식작업이 잘 등록 되면 작업목록에 요청방법과 함께 작업 현황에 초록불이 들어옵니다.

인식 작업이 완료되면 인식 결과 수정 에디터를 실행하여 인식 대상 미디어 파일과 인식된 텍스트를 함께 확인 할 수 있습니다. 또한, 인식 결과를 편집하고 원하는 형식으로 내보낼 수 있습니다.
4. 인식 결과 편집 및 내보내기

필요한 경우, 인식 결과를 편집해주면 됩니다.
인식 결과 내보내기


Object Storage > ptty-bucket 에 저장이 잘 된 것을 확인할 수 있었습니다.
인식 작업 삭제

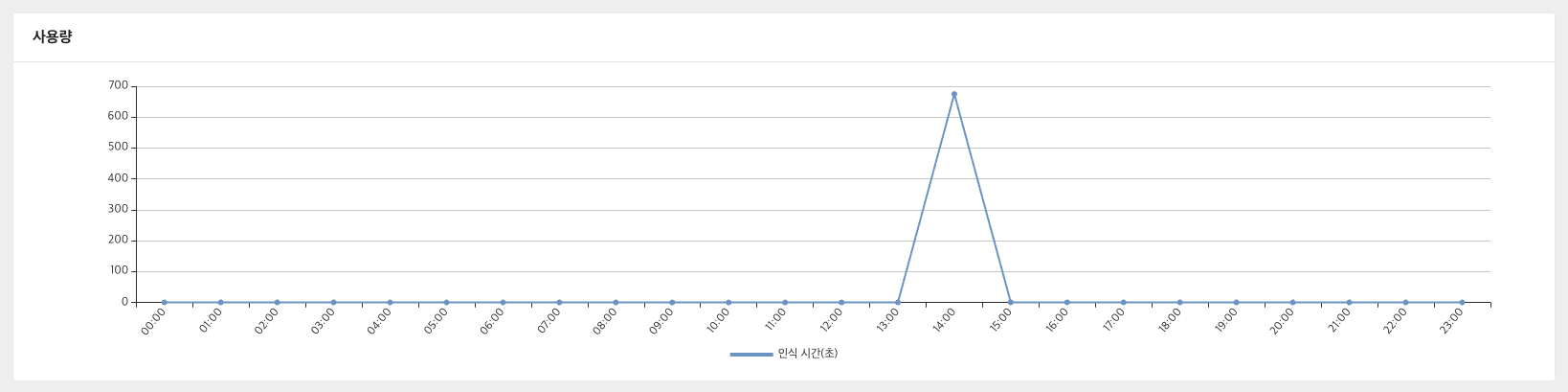
사용량 확인 및 점검
도메인 코드 별 CLOVA Speech > Usage 에서 인식 횟수(건)과, 사용량을 확인 할 수 있습니다.

사용 후기
CLOVA Speech 를 직접 사용해보니 어떻게 네이버 뉴스가 CLOVA Speech 를 사용해 자막을 내보내고 있는지 기술력을 체감할 수 있었습니다. 어려운 용어들도 많은데 인식률이 많이 뛰어나 어렵지 않게 영어와 한국어 모두 잘 인식되어 텍스트로 변환되었고, 나중에 내보내기할때 확장자가 다양해서 직접 영상 자막으로도 편집이 가능해 편리함이 돋보였습니다.
'NCP' 카테고리의 다른 글
| [NCP] CLOVA OCR 사용하기 (1) | 2023.10.17 |
|---|---|
| [NCP] Bare Metal Server A100 사용하기 (0) | 2023.09.25 |
| [NCP] Clova Dubbing 이용하기 (0) | 2023.08.23 |
| [NCP] 홈 경로에 configure 파일 넣기 & ncloud 파일을 경로에 상관없이 실행하도록 설정하기 (0) | 2023.08.10 |
| [NCP] Cloud Security Watcher 사용하기 (1) | 2023.08.10 |